When using Acunetix to scan for vulnerabilities, it is imperative that all locations are discoverable by DeepScan, as missing even one path will leave your application vulnerable to a potential attack.
To check if Acunetix identified all the locations in your application, navigate to Scans -> [YOUR SCAN] ->Site Structure. From there, Acunetix will display all the directories discovered by the crawler.

If certain directories have not been scanned, then there might be an issue that is preventing the crawler from accessing those directories.
Here we discuss some possible causes for Acunetix omitting to scan part of the site, as well as solutions:
Configure a Login Sequence for your site
Most sites have certain areas which are restricted to certain users only, in which case, you can create a Login Sequence to instruct the crawler on how to login. Here are some things to look out for when configuring a Login Sequence for your site:
- After configuring the Login Actions, use the Play button to confirm that Acunetix can automatically replay the Actions recorded

- Ensure that you configure all requests which can cause the session to be invalidated as a Restricted link. At minimum, this will include Logout actions (links, buttons, etc), however you should also lookout for actions which might impair the user account or the site, such as Delete User, or Delete Database options.

- In the Detect User Session tab, use the Check Pattern option to confirm that the Session Validation Pattern configured for the login sequence is valid. This is important as it will allow to scanner to know if it still has a valid session, which usually translates to still being logged in. An incorrect Session Validation Pattern will cause one of the following:
- The scanner to not realise that it has been logged out – in this case parts of the site will not be scanned, and this will be evident in the Site Structure tab for the scan.
- The scanner to think that it has been logged out when in reality it has not – this will cause the scanner to replay the login actions when unecessary, resulting in a longer scan.

More information on how to setup an LSR can be found here:
https://www.acunetix.com/blog/docs/acunetix-wvs-login-sequence-recorder/
https://www.acunetix.com/blog/docs/session-detection/
Case sensitive paths
Some servers make use of case sensitive paths. In this case, www.example.com/backups will not be treated the same as www.example.com/Backups. For such servers, you can configure Acunetix to make use of Case Sensitive Paths from the Crawl options when scanning the Target.

Pre-seeding a crawl
Acunetix usually does a very good job of finding links and pages that are being linked from the website itself. This might not always be possible, such as for example when pages in the web application are not linked to, from the main site. In this case, you can provide a list of links which you think Acunetix will have difficulty identifying, and these links will be used to seed the scan. The feature is called Import Files, and accepts a number of file formats including text files, Fiddler and BURP exports, HAR files, Swagger and WSDL API definitions.
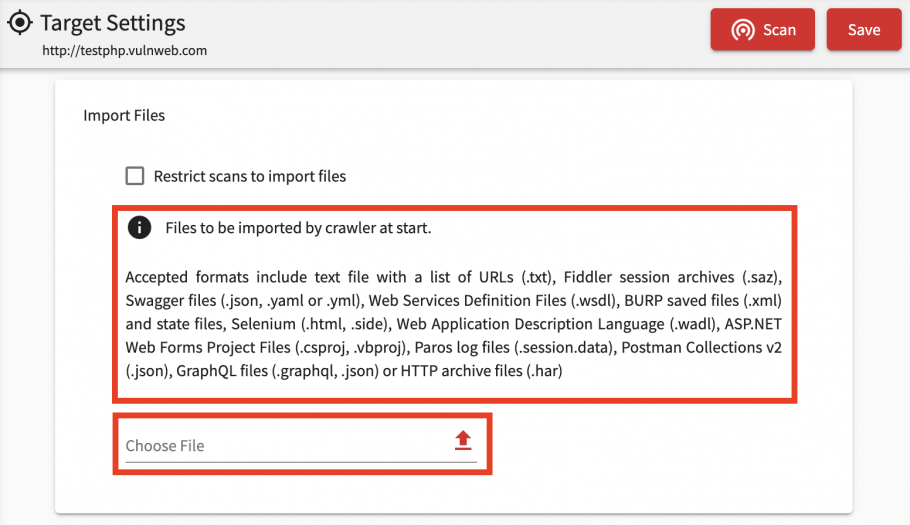
A guide on how to Pre-seed the crawl
AcuSensor™
When AcuSensor™ is used, Acunetix has information on all the paths of the web application, thus ensuring a comprehensive scan. Since AcuSensor™ has access to the back-end of the application it can request a directory listing and supply it back to the scanner for further analysis. AcuSensor™even goes further by discovering hidden GET and POST inputs and presents them to Acunetix for testing, making crawling much more thorough and ensuring full coverage.
AcuSensor is available for PHP, .NET and JAVA web applications.
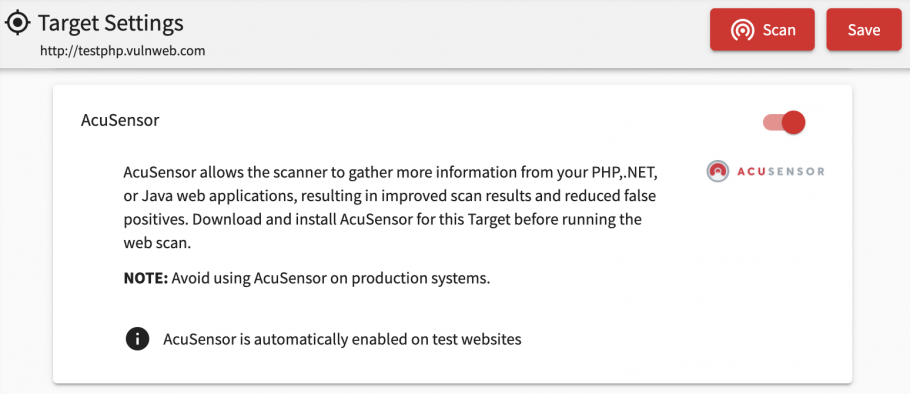
Guide on how to install and use AcuSensor
HTTP Authentication/Client Certificates
Should part of the web application require HTTP Authentication, you can include this in the HTTP Authentication settings that can be found under the HTTP tab of a selected target. From here, one can insert the Username and Password for the HTTP Authentication of the selected target. The same goes for client certificates.

More on the subject can be found here:
https://www.acunetix.com/blog/docs/scan-http-authentication-protected-area/
https://www.acunetix.com/blog/docs/using-client-certificates-acunetix/
Trailing forward-slash
Last but not least, be aware that if when setting up a target, you leave a trailing “/” after the URL, Acunetix will automatically crawl the address and the subdirectories of that location. Acunetix will not attempt to scan anything above the location configured.
For example, if you configure https://www.example.com/blog/, Acunetix will not attempt to scan https://www.example.com/. It will restrict the scan to anything below the https://www.example.com/blog/ location.
Get the latest content on web security
in your inbox each week.
THE AUTHOR


