Configuring Targets
Targets are the websites and web applications that you would like to scan using Acunetix. In Acunetix, you can also configure Network assets as Targets. These need to be configured in Acunetix before they can be scanned. Once configured, a Target can be scanned as often as required.
This guide shows you how to configure the settings for Targets after you have added them to Acunetix.
How to access Target Settings
A Target's basic details are listed at the top of the Target Settings page. To access this page:
- Select Targets from the Acunetix menu.
- Click on a Target Address from your list of Targets.
The Target Settings page is now displayed for your selected Target Address. From this page, you can adjust various settings for your target.
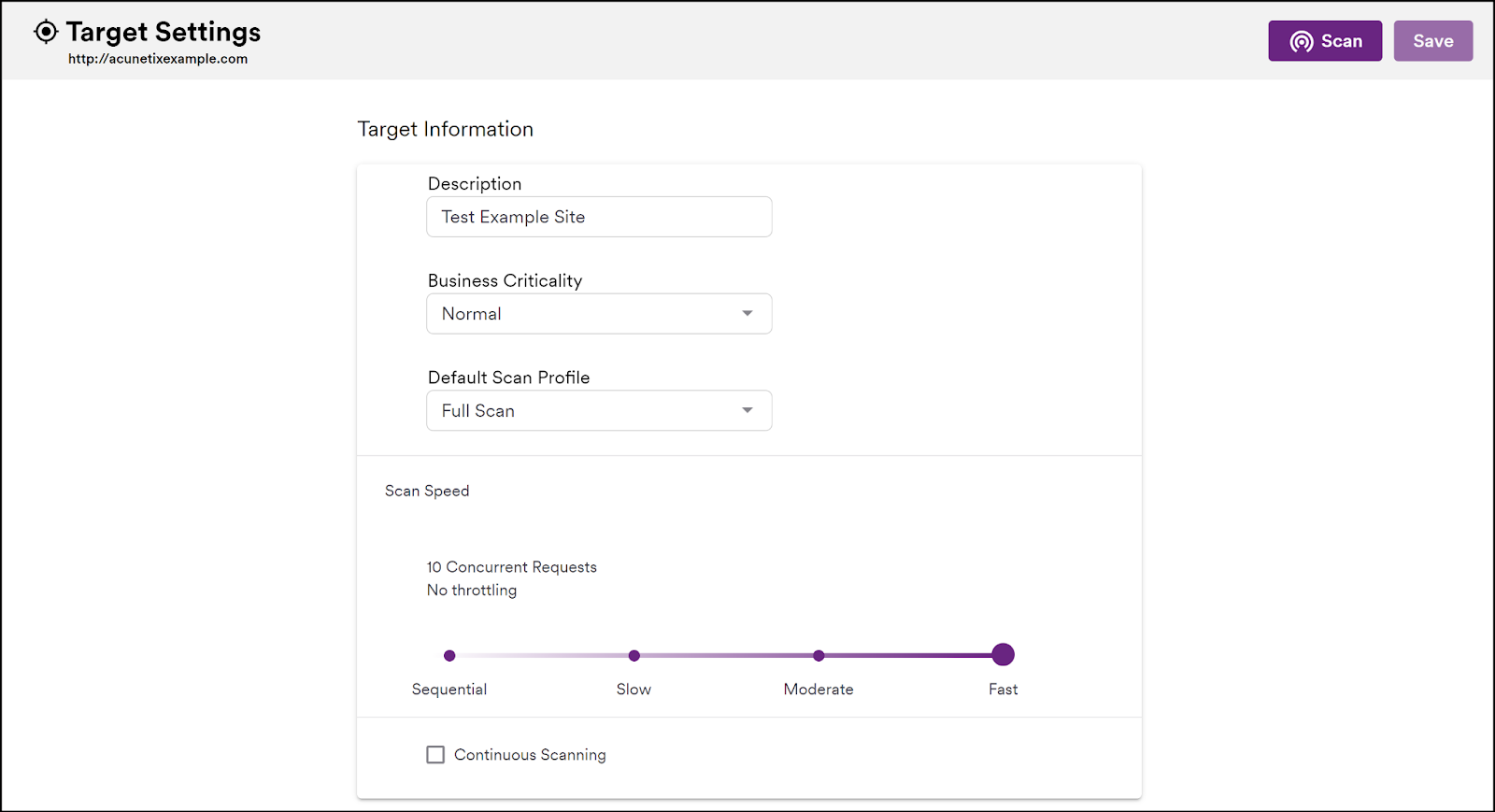
How to configure Target Settings
The sections below explain each of the configuration options available on the Target Settings page.
Business Criticality
You can assign a different level of business criticality (Low, Normal, High, Critical) from the default labeled Normal. This will give you the opportunity to filter scans and vulnerabilities based on this metric, allowing you to focus on the more critical items in your web inventory if necessary.
Default Scan Profile
Every time you start a scan on a target, you can specify the scan profile to use, with the default scan profile being Full Scan. You may decide, however, to change the default scan profile for a particular target. For example, if you consider one of your targets to be a Low Business Criticality target, you may set your default scan profile for that target to be the High Risk profile. Following this change, every time you launch a scan on this target, the default scan profile will be set to High Risk.
Scan Speed
Your target may be adversely affected by high speed or high intensity (simultaneous requests) scans or may trigger defense mechanisms that invalidate your scan results.
You can adjust the scan speed to any of the following:
- Fast (default): 10 concurrent requests, no throttling
- Moderate: 5 concurrent requests, send requests every 20 milliseconds
- Slow: 2 concurrent requests, send requests every 50 milliseconds
- Sequential: 1 concurrent request, no throttling
For information about the Continuous Scanning option, refer to Scheduling Continuous Scanning.
Default Agent
This is the agent that is used by the target. The default agent for all new targets on Acunetix Online is the Cloud Agent. Cloud Agents are managed by Invicti and they can reach any publicly accessible site on the internet. If you have any internal agents set up, these can be selected using the Agent drop-down in the Default Agent section of a target's settings page. For more information about internal agents, refer to Introduction to internal site scanning.
For more information about the Configure proxy server for agent option, refer to:
- Acunetix Online: Target Settings - Proxy Server
- Acunetix Premium+ Online: Installing internal agents with proxy settings
Site Login
This section contains options to enable Acunetix to scan restricted areas within a web application. This can be achieved by providing a username and password for Acunetix to automatically log in to restricted areas of a web application or through the use of a pre-recorded login sequence or OAuth2 authentication mechanism.
For more information, refer to Target Settings - Site Login (scan restricted areas).
Business Logic Recorder
Many web applications utilize dynamically expanding, multi-step, or multi-page forms. This means that a "first stage" form is presented to the user, and when the user inserts information into this first stage, the information provided will determine how the form will change, in the next step or page. The Business Logic Recorder allows you to create a string of actions for the Acunetix scanner to follow so that it can properly navigate multi-part forms. For instructions on how to use the Business logic recorder, refer to the linked document.
SSH Credentials
If your target web application requires SSH credentials in order for the Acunetix scanner to access it, you can provide these as either a private key or by adding a username and password to the Target Settings. Click the toggle in the SSH Credentials section to expand and enable this setting.
AcuSensor
Acunetix AcuSensor increases the accuracy of an Acunetix scan by improving the crawling, detection, and reporting of vulnerabilities while decreasing false positives. AcuSensor can be used on .NET (including .NET core), JAVA, PHP, and Node.js web applications. The AcuSensor Agent needs to be deployed on your target web application. For more information, refer to Target Settings - AcuSensor and Introduction to deploying AcuSensor.
Crawling
For each Target, you can configure crawling options, including:
- User-Agent String
- Case Sensitive Paths
- Limit Crawling to address and sub-directories only
- Excluded Paths
- Adding paths via Import Files / API Definitions
HTTP
For each Target, you can configure HTTP options, including:
Advanced Options
For each Target, you can configure Advanced options, including: